【Part.2】Advanced Troubleshooting of VMware ESXi Server 6.x for vSphere Gurus
Overview
はじめに
前回の記事の続きです。今回は VMworld 2017 SER2965BU のセッションでの 4:28 ~ 26:54 頃までの内容、七つ道具x3セットの1セット目である7つのログについて見ていきます。
- vmksummary.log
- boot.gz.log
- hostd.log & hostd-probe.log
- vmware.log
- vmkernel.log
- vobd.log
- fdm.log
この辺りの基本的なログの特徴を理解しつつログとの対話を重ねていくと、障害時などにログから原因の推測などがしやすくなると思います。なお、実際に出力されるメッセージは事象によりケースバイケースで異なるため、今回の記事ではセッションと同様、ログファイルの概観とログを見るためのポイントを押さえるといった程度に留めます。
免責事項
当サイトでは可能な限り公式から情報公開されている内容などの情報源を記載するようにはしていますが、記事を参考にしたことで障害調査が遅延したなど何らかの問題が発生した場合においては一切の責任を負いかねますので、予めご了承いただきますようお願いいたします。
ログファイルの場所
まずログを見るために最も重要な点はログファイルの場所です。基本的には /var/log 配下にカレントのログなどが、/var/run/log 配下にローテートされたログファイルも含めて配置されています。
なお、ログの実体は既定でスクラッチパーティション (ESXi 7 では ESX-OSData 領域) に格納されています。何らかの要因でスクラッチ領域が未設定だとログが /tmp 領域(=メモリ上)に配置され、ESXi の再起動でメモリ内容の破棄とともにログが消失してしまいます。
特に ESXi が USB メモリや SD カードから起動される環境ではスクラッチ領域の作成自体が行われませんので、ESXi のインストール後に設定が必要になることにご注意ください。スクラッチ領域の詳細は以下の KB1033696 をご確認いただければと思います。
ESXi 7.x/6.x/5.x/4.x の永続的スクラッチの場所の作成 (1033696)
それではログの場所も確認できたところで順にログファイルを見ていきます。
vmksummary.log - 突然のホスト再起動
突然、ある ESXi ホストが再起動したといったケースで見るべきログが vmksummary.log です。まず、適切な ESXi の再起動が行われた場合、ESXi は自分から再起動や起動を行うので、vmksummary.log には以下のように Host is rebooting (=今から再起動する) と Host has booted (=起動がおわった) の記録が残ります。
12020-05-20T14:00:01Z heartbeat: up 0d8h47m9s, 7 VMs; [[87812 vmx 7534364kB] [82559 vmx 16726548kB] [68485 vmx 16762084kB]] [[87812 vmx 0%max] [82559 vmx 0%max] [68485 vmx 0%max]]
22020-05-20T14:26:45Z bootstop: Host is rebooting
32020-05-20T14:41:43Z bootstop: Host has booted
42020-05-20T15:00:01Z heartbeat: up 0d0h19m48s, 4 VMs; [[67968 vmx 6291080kB] [68442 vmx 11900344kB] [68617 vmx 16614596kB]] [[67968 vmx 0%max] [68442 vmx 0%max] [68617 vmx 0%max]]
これに対して適切でない再起動が発生した状況、例えばサーバの電源ボタンや IPMI 等を利用した電源リセットやハードウェア障害で装置が再起動したなど、ESXi で再起動処理が走らないような状況を考えてみます。この場合、ESXi は自分では起動しかできなかったため Host is rebooting は記録されません。
12020-09-05T14:00:00Z heartbeat: up 0d2h7m27s, 0 VMs; [[65846 vmsyslogd 14196kB] [67536 vpxa 21360kB] [67319 hostd 61388kB]] []
22020-09-05T14:31:18Z bootstop: Host has booted
ESXi で致命的なエラーが発生してクラッシュして PSOD (紫色の診断画面) が発生した場合を考えてみます。以下は Nested ESXi ですが、ESXi 7.0 で NMI を発行して意図的に PSOD を起こしています。後ろから2~3行目を見るとコアダンプがファイルとして出力されていることが分かります。ESXi 6.7 以前では Disk dump として表示(診断パーティションへ保存)されることも多いと思います。
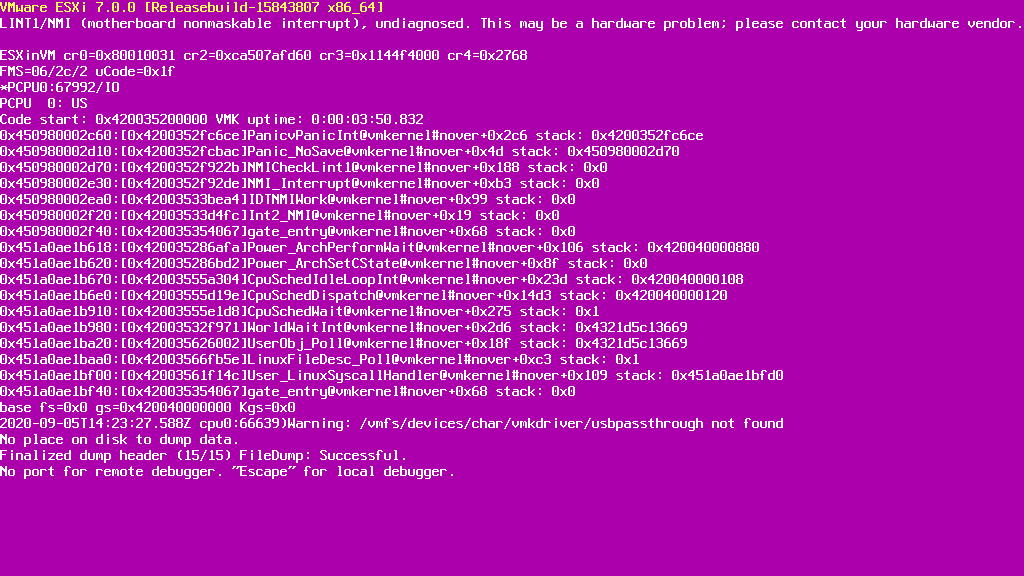
この場合も ESXi の再起動処理は行われていないため Host is rebooting は記録されません1。ただ、ESXi の起動時にディスク上に保存された PSOD 時のコアダンプを検出して core dump found といった記録を伴うことが多いです。
12020-09-05T14:00:00Z heartbeat: up 0d2h7m27s, 0 VMs; [[65846 vmsyslogd 14196kB] [67536 vpxa 21360kB] [67319 hostd 61388kB]] []
22020-09-05T14:31:18Z bootstop: Host has booted
32020-09-05T14:31:18Z bootstop: file core dump found
なお、vmksummary.log の特徴として一時間毎にホストの Uptime や実行中 VM 数と合わせて記録されます。このため、vmksummary.log の記録が途切れた場合、その直近の記録から一時間後までの間に何か致命的な状況(例えば電源 OFF や PSOD)が起こったと判断できます。
vmksummary.log のフォーマットやホストでの電源操作の有無の判断などは以下の KB も参考にしてみてください。KB2004566 はメッセージが古いバージョンのものですが、vmksummary.log を目grepする分には支障はないと思います。
- Format of the ESXi 5.x vmksummary log file (2004566)
- Determining why an ESXi host was powered off or restarted (1019238)
boot.gz - ESXi の起動が遅い問題
boot.gz は ESXi の起動プロセスが記録されるログで、ESXi の起動処理が遅かったり、起動プロセス中に ESXi がハングしたりした場合には boot.gz を見ます。こちらのログは /var/log/boot.gz に存在しますが、圧縮されているので以下のように zcat で展開して確認します。
1# zcat /var/log/boot.gz | less
ESXi のブートプロセスとして、大まかにはまず VMkernel のロード処理が出力され、その後に jumpstart という各種モジュール(例えばドライバ)をロードするためのモジュールが実行されます。これらの処理の経過が boot.gz に記録されます。jumpstart についてはタイムスタンプと合わせて記録されるため、これを眺めることで他の処理と比べて時間がかかっている処理を見つけられます。
ブートが遅い事象の例としては KB1016106 があります。個人的にはブートが遅い時は大体この事象が起きている印象があります。
- RDM を含む MSCS ノードによって使用されている RDM LUN を認識できる ESXi/ESX ホストで、起動または LUN の再スキャンに時間がかかる場合がある (1016106)
- ESXi/ESX hosts with visibility to RDM LUNs being used by MSCS/WSFC nodes with RDMs may take a long time to start or during LUN rescan (1016106)
詳細は省略しますが、MSCS/WSFC でのクラスタリングを共有の物理互換モード RDM で組んだ場合、MSCS/WSFC の仕様上、Windows ゲストにより RDM LUN がロックされます。この状態で ESXi の起動や再スキャンを行うと Windows ゲストによる既存のロックと ESXi の新しいロックが競合して処理に非常に時間がかかるという事象です。この対応には RDM に永久予約を設定する必要があります2。
KB1016106 の事象が ESXi のブートプロセスで発生した場合には boot.gz を見ることになると思います。しかし、この事象は元々は vSphere 上で WSFC を組むガイドラインに準拠せず設定が漏れた場合に発生します。このため、ブートプロセスが遅いとなったら真っ先に物理互換 RDM で WSFC 等のゲストクラスタリングを組んでいないか、ガイドラインを守っているかを確認する方が良いと思います。
ESXi 5.0は、MSCS クラスタのデバイスで RAW デバイス マッピング (RDM) LUN が使用されているかどうかを判別するために別の技術を使用します。そのために、MSCS クラスタに参加している各デバイスを「永久予約」としてマークする構成フラグが導入されています。RDM LUN を使用するパッシブ MSCS ノードをホストする ESXi ホストの場合は、次の esxcli コマンドを使用してデバイスを永久予約としてマークします: esxcli storage core device setconfig -d <naa.id> –perennially-reserved=true。詳細は、KB 1016106 を参照してください。
なお、DCUI で Alt + F12 を押下すると VMkernel のログが見られるため、こちらからライブ感を持ってトラブルシューティングをすることも出来なくはないです。ESXi Shell が起動できずログバンドルも取れないなどの緊急時にはここから何か得られるか見ることになると思います3。
ESXi のダイレクト コンソール インターフェイスについて
セッション動画の 9:28 頃から ESXi のログが永続化されてない場合にシリアルポート経由でログを転送する方法について説明されています。ただし動画内でも言われている通り、ログが永続化されない状況はワーストケースですので本記事では割愛します。
hostd.log & hostd-probe.log - ホストが応答なし
hostd は ESXi の中核のプロセス(Userworld)です。hostd に問題が発生すれば vpxa - hostd 間のやり取りができなくなり、vCenter Server からは ESXi が応答なしになります。ping などの L2/L3 のネットワーク疎通には問題が無いにもかかわらず、Host Client からの接続など ESXi への直接接続が行えない場合には hostd に問題が発生している可能性があります。
hostd-probe プロセスは hostd に定期的にクエリを発行して死活監視をしています。hostd からの応答がなくなると hostd detected to be non-responsive といったメッセージが hostd-probe.log に記録されます。
hostd に異常がある場合は ESXi の管理エージェントの再起動を行うことになります。もしログで明らかに hostd の問題であることが確認ができているようであれば、サポートに何か追加で事前に採取すべき資料があるか確認することが推奨されるとのことです4。
管理エージェントの再起動の実施後、hostd が正常に動作しているか確認する簡易な手順としては、KB2012964 などで言及されている以下の vim-cmd コマンドで仮想マシンの一覧を表示してみる、Host Client で ESXi に接続してみるなどの方法が考えられます。
1# vim-cmd vmsvc/getallvms
前回記事や上述の内容にもある通り hostd は ESXi の中核となるプロセスです。以下の KB2012964 にあるような ESXi で実行されるタスクはおおむね hostd.log に何らかの記録が残ると思いますので、何か ESXi のタスクで問題が発生した場合には hostd.log を見てみるのも一つ有効かもしれません。
Performing common virtual machine-related tasks with command-line utilities (2012964)
vmware.log - 仮想マシンにおける問題
セッションでは以下の KB1007969 の問題により仮想マシンの起動が失敗したケースについて言及されています。こちらの問題は、何らかの要因でスナップショットの親ディスクの CID と子ディスクが持つ親 CID が不一致になり、スナップショットチェーンが破損してしまった場合に発生します。
仮想マシンのログに、次のようなエントリが含まれている。
vmx| DISKLIB-LINK : Attach: Content ID mismatch (d0fdb25b != ef4854ee).
vmx| DISKLIB-CHAIN : “/vmfs/volumes/4a365b5d-eceda119-439b-000cfc0086f3/examplevm/examplevm.vmdk” : failed to open (The parent virtual disk has been modified since the child was created).
例えば、親ディスクを別の仮想マシンに既存のハードディスクとして追加してパワーオンすると、仮想マシンに構成されてしまった親ディスクの CID が更新され、元のスナップショットチェーンが破損します。これにより仮想マシンをパワーオンしようとするとタスクがエラーになり上述のようなメッセージが vmware.log に記録されます。
KB1007969 の他にも、一般にスナップショットの作成や削除・統合の詳細な内容は vmware.log によく出力されます。これらの操作で問題が発生した場合は vmware.log に何か詳細な情報が無いか調べてみるのも良いでしょう。Windows の静止スナップショットでは VSS が使用されますが、ゲスト上の VSS による静止点確保に失敗すると VSS のエラーコードが vmware.log に記録される場合もあります。
- ボリューム シャドウ コピー サービス (VSS) 静止関連の問題のトラブルシューティング (1007696)
- スナップショット作成操作が、停止した仮想マシンでの I/O 保留時間制限を超えたため静止スナップショットを作成できない (1018194)
- Quiescing snapshots in an ESXi host fails with the error: The guest OS has reported an error during quiescing. The error code was: 5 The error message was: Asynchronous operation failed: >VssSyncStart (2090545)
仮想マシンやゲストOSで電源操作を行った場合も特徴的なメッセージが vmware.log に残ります。これに関しては以下の KB1019064 が詳しいのでこちらをご参照ください。
仮想マシンがパワーオフまたは再起動した原因を特定する (1019064)
なお、vmware.log は仮想マシンのパワーオンや vMotion のように新しい仮想マシンプロセスが生成されるタイミングでローテーションが行われます。これらの操作/処理が頻繁に発生するとすぐにログが流されてしまう場合もあります。
環境や運用によってはログの世代数を変更する、問題発生時に追加の作業を行う前に速やかにログを採取する、といった対応が必要になる場合があるかもしれません。後者は vmware.log に限らず事象発生当初の状態の保全という意味では重要です。
vmkernel.log - ストレージやドライバの問題
vmkernel.log は VMkernel のログで様々な内容が記録されますが、主にストレージ関連の問題が発生した際に見ることが多いログです。また、ドライバによるエラーやイベントの記録もこのログに記録されます。
例えば VMFS データストアや HBA が検出されない、LUN やパーティションや VMFS 自身に何らかの問題があるといった場合、vmkernel.log にそれらを示唆する記録が出力されることが多いです。
ここで「示唆する」という言葉を使ったのは、ストレージ関連の記録は必ずしもログに「こういう問題が出てますよ!」といった具体的なエラーを示すメッセージが出るわけではないからです。ストレージの記録は主に SCSI Sense Code として出力されるため、何が起きているか以下のような資料を参考にしつつ解釈していく必要があります。
- Interpreting SCSI sense codes in VMware ESXi and ESX (289902)
- VMware ESXi SCSI Sense Code Decoder
- SCSI Status Codes
- 6.18. host_status | The Linux SCSI Generic (sg) HOWTO
- 21. Error handling | The Linux SCSI Generic (sg) HOWTO
- SCSI ASC/ASCQ Assignments
- Understanding SCSI plug-in NMP errors/conditions in ESX/ESXi 4.x/5.x/6.0 (2004086)
SCSI コマンドのエラーメッセージは主に「ScsiDeviceIO」から始まります。一例として、KB289902 にある以下のメッセージを解釈してみましょう(セッション動画もほぼ同じ内容のメッセージです)。
2011-04-04T21:07:30.257Z cpu2:2050)ScsiDeviceIO: 2315: Cmd(0x4124003edb00) 0x12, CmdSN 0x51 to dev “naa.600508e000000000c9f6baa7c19f6900” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0.
まず、最初の Cmd 0x12 は SCSI コマンドの種類を指します。この場合は 0x12 = INQUIRY を発行していることが分かります。
次に、failed の後の H: D: P: はそれぞれ Host Code (=HBA 側)、Device Status Code (=ディスク側)、Plugin Error Code (VMware 固有のコード) を指します。どれも 0x0 は問題ないことを示すため 0x0 以外のものを見ます。上述のメッセージの場合、D:0x2 から Device/Status codes = Check Condition となっています。
コマンドの結果として Check Condition が返された場合は Sense Data (sense data: 0x5 0x24 0x0) に詳細な内容が含まれるため、こちらを見ます。Sense Data は左から Sense Key、ASC (Additional Sense Code)、ASCQ (Additional Sense Code) です。今回は Sense Key = 0x5 = ILLEGAL REQUEST、ASC/ASCQ = 24/00 = INVALID FIELD IN CDB となります。
これらの内容から、このメッセージは「INQUIRY コマンドを発行したところデバイスには不正なリクエストとして判断された」と解釈できます。では、このエラーメッセージは実際に問題を示しているものでしょうか?
KB1010244 を見ると、そもそも当該コマンドはデバイスによって完全な情報を提供しない場合もあり、必ずしも問題を示すものではないということが分かります。従って、このコマンドと結果の組み合わせのメッセージが何らかの問題を示すかはストレージの仕様に依存することになります(問題ではないケースが多い印象です)。
リスキャン操作中の VMkernel ログ内の SCSI Check Condition について (1010244)
SCSI INQUIRY は、ユニット シリアル番号(ページ 0x80)、デバイス識別番号(ページ 0x83)、管理ネットワーク アドレス(ページ 0x85)を含む、LUN からの重要プロダクト データ (VPD) ページ情報を要求します。
SCSI デバイスが特定の VPD ページをサポートしない場合、SCSI デバイスはこの要求にエラーで応答する場合があります。具体的には、SCSI ステータス 2 (Check Condition)とともに、認識キー 5 (Illegal Request)、および追加の認識コード (ASC) と追加の認識コード修飾子 (ASCQ) (0x20/0x0 または 0x24/0x0 に設定されている)を返す場合があります。
本章の冒頭に記載の通り、vmkernel.log には他にもドライバによるエラーやイベントの記録も出力されます。例えば、物理 NIC でのリンクダウンやリンクアップは分かりやすいところです。しかし、これもメッセージの記録のされ方などはドライバに依存するため、メッセージの決まったフォーマットはありません。
このように vmkernel.log にはストレージやドライバの問題が記録されますが、解釈が単純ではないケースも多いです。vmkernel.log 以外のログにも当てはまりますが「全てのエラーメッセージが実際の問題を示しているとは限らない」「適切なトラブルシューティングは関連するコンポーネントにも依存する」といったことを意識しておくことが非常に重要です。
vobd.log - ストレージやネットワークの問題
vmkernel.log は慣れないと読み解くことがかなり難しいですが、vobd.log は VMkernel で検出された問題をより抽象度が高いイベントとして記録されるため読みやすいログです。特にネットワークやストレージへの接続が単純に切断されたようなケースでは最初に見るべきログです。vobd.log に出力される内容は vCenter Server のイベントとしても出力されることが多いです。
例えば、ホストの NIC がリンクダウンした場合、以下のようにリンクダウンと影響を受けるポートグループが記録されます。この場合は冗長性を完全に喪失しネットワーク接続までロストした記録も出ています。
12020-09-05T16:04:56.742Z: [netCorrelator] 5435478730us: [vob.net.pg.uplink.transition.down] Uplink: vmnic0 is down. Affected portgroup: Management Network. 0 uplinks up. Failed criteria: 128
22020-09-05T16:04:56.742Z: [netCorrelator] 5435478768us: [vob.net.vmnic.linkstate.down] vmnic vmnic0 linkstate down
32020-09-05T16:04:58.001Z: [netCorrelator] 5436738494us: [esx.problem.net.connectivity.lost] Lost network connectivity on virtual switch "vSwitch0". Physical NIC vmnic0 is down. Affected port groups: "Management Network"
他には、ESXi からストレージデバイスへのパスがダウンし、パスの冗長性が低下した場合には以下のように記録されます。この場合は redundancy が lost した記録までは出てないため「まだパスは生きてて冗長性もある」と推測できます。
12020-08-11T04:12:52.583Z: [scsiCorrelator] 53521051215us: [esx.problem.storage.redundancy.degraded] Path redundancy to storage device naa.6a4badb04d1b31001fdef7e509ec5276 degraded. Path vmhba65:C0:T5:L1 is down. Affected datastores: "DS_123".
ネットワークの問題による iSCSI 接続の切断であれば KB2001447 のような記録が出力されます。
12017-07-27T15:41:42.583Z: [iscsiCorrelator] 535636694us: [vob.iscsi.target.connect.error] vmhba65 failed to login to iqn.1992-08.com.netapp:sn.151696808:vf.23fc0bc3-addf-11e2-a25d-123478563412 because of a network connection failure.
もし直前に上述のような NIC のリンクダウンの記録があれば、接続先のスイッチとのリンクの問題に起因すると判断したり出来ます。特に無いようであれば vmkernel.log 上で詳細な情報が出ていないか、SAN 上やストレージに問題が無いか、トラフィックの輻輳が発生していないかなどを切り分けていきます。
このように vobd.log は読める英語でメッセージが出力されるので、ネットワークやストレージの問題が出た場合は vobd.log を見て状況の概観を掴んだ後に vmkernel.log で詳細を見ていくなどのアプローチも良いでしょう。なお、ネットワークの問題の場合は vmkernel.log での確認ではなくパケットキャプチャでの確認が必要となるケースも多いと思います。
fdm.log - vSphere HA の問題
vSphere HA の記録、例えばあるホストの障害時に停止した仮想マシンが他のホストでパワーオンされたかどうか等は fdm.log に記録されます。Fault Tolerance が有効の場合はそのログもこちらに出力されます。
fdm.log を読み解いていくには以下の3つのポイントを押さえることが重要です。
- ホストの HostID
- ホストが slave か master か
- ホストが隔離された(isolated)かどうか
まず KB2037000 のようにいずれかの ESXi の ESXi Shell で /opt/vmware/fdm/fdm/prettyPrint.sh hostlist コマンドを実行すると、以下のように vSphere HA が有効な同一クラスタに参加している ESXi の HostID やホスト名、ビルド番号や vmnic の MAC アドレスなどが確認できます。
1<obj xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:csi" versionId="1.0" xsi:type="CsiHostList">
2 <faultDomainId>acf001e5-2449-46a7-a882-82c069b29111-25037-6bc5c5f-vcsa01a</faultDomainId>
3 <version>29</version>
4 <host>
5 <hostId>host-25029</hostId>
6 <hostName>esxi70-01.jangari.local</hostName>
7 <sslThumbprint>71:CC:28:47:4B:B8:50:20:9E:73:23:78:5E:D2:58:6A:BD:54:ED:62</sslThumbprint>
8 <ipAddress>10.0.1.1</ipAddress>
9 <mac>00:50:56:ad:c9:82</mac>
10 <mac>00:50:56:ad:d9:49</mac>
11 <vmkNics>vmk1</vmkNics>
12 <hostdPort>443</hostdPort>
13 <version>7.0.0</version>
14 <build>15843807</build>
15 <hostInfoState>KNOWN</hostInfoState>
16 </host>
なお、上記例は vmk1 で vSAN を有効にしている環境で採取したため、vSphere HA の通信には vSAN ネットワークが使われることから vmkNics が vmk1 となっています。vSAN 以外の環境であれば管理トラフィックの VMkernel ポートが vSphere HA の通信に使用されます。
自身の hostId が見つかったら、fdm.log からその内容を探してみます。fdm.log にはよく以下のようなメッセージが出力されています。こちらのメッセージから自身は Slave であること、マスターホストは host-25033 の hostId を持つ別のホストであること、自身は隔離状態ではない、といったことが分かります。
12020-08-25T11:05:29.949Z info fdm[565994] [Originator@6876 sub=Cluster opID=SWI-3ab50c2a] hostId=host-25029 state=Slave master=host-25033 isolated=false host-list-version=4 config-version=5 vm-metadata-version=10 slv-mst-tdiff-sec=0
前回の記事でも少し書きましたが、vSphere HA はマスターホストが他のホストの監視やホスト障害の判断などの役割を担っています。マスターホストが確認できれば、マスターホストの fdm.log を確認することでホスト障害時の vSphere HA の処理の流れを確認することが出来ます。
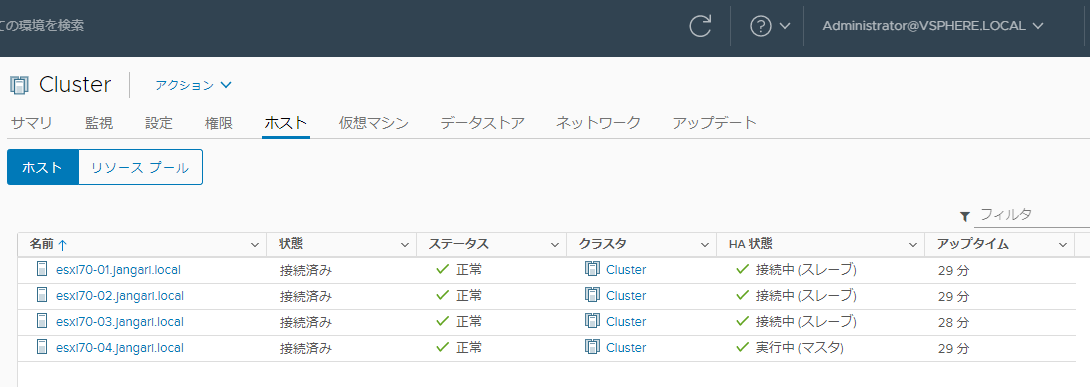
マスターホストの特定は上述の fdm.log のメッセージの他にも、ホストの [サマリ] タブ等からも確認出来ます。クラスタの [ホスト] タブを見ると [HA 状態] 列から一覧で確認できるので、こちらで探すのも早いかもしれません。
To be continued…
今回は ESXi のログファイルについて見ていきました。次は ESXi のコマンドについて見ていきます。
-
ESXi で PSOD が発生した場合、既定では自動的に再起動はしません。この動作は KB2042500の手順で変更できますが、自動的に再起動すると PSOD のスクリーンショットを取りそこねる可能性が非常に高いです。これにより PSOD の調査が出来なくなるケース(ストレージ周りが起因の場合は特に)もあることから、KB2042500 に記載のとおり既定値のまま触らない方がよいです。 ↩︎
-
RDM の永久予約は vSphere 7 で GUI から一括設定が可能になりました。ただ、vSphere 7 なら Clutered VMDK (FC only) や vSAN での WSFC がサポートされているので、使えるならこれらを使った方が・・・という感じはあります。詳細は KB79616 を参照してください。 ↩︎
-
個人的な見解ですが、ESXi Shell や DCUI すら操作できないような状況は、既に ESXi の再起動が必要になっている状況の可能性が高い印象です。滅多に無いと思いますが万が一そのような状況まで陥ってしまった場合には、再起動なしで復旧できるといった希望はあまり持たない方が良いと思っています。 ↩︎
-
動画内で livecore という単語が出ていますが、ドキュメントやナレッジベースなどの VMware から正式に公開されている情報は見当たりませんでした。恐らくこの内容と推測されますが、仮にそうでもサポート指示がない限りサポートされないと思いますのでこれ以上は言及しません。 ↩︎